문서 하나로 정리하는 DynamoDB 설계 입문
AWS에서 제공되는 NoSQL 데이터베이스 서비스에는 몇 가지가 있지만, 가장 널리 사용되는 것은 DynamoDB입니다. DynamoDB는 완전 관리형(Full-Managed) 서버리스 NoSQL 데이터베이스로, 다음과 같은 특징들을 가지고 있습니다.
- 완전 관리형: DB 설치나 세부 설정, 확장/축소 등을 사용자가 관리할 필요가 없습니다. 모두 AWS에서 자동으로 관리합니다.
- 서버리스: 데이터를 저장한 만큼, 데이터베이스를 읽고 쓴 만큼에 대해서만 비용을 지불하면 됩니다.
DynamoDB의 가장 큰 특징으로는 ‘모든 규모에서 매우 빠른 성능을 보장’ 한다는 점입니다. 이 말은 데이터가 얼마나 많든, 요청이 얼마나 많이 들어오든, ‘설계만 제대로 되어 있다면’ 성능이 보장된다는 뜻입니다. 반대로 말하면, ‘설계가 제대로 되어 있어야’ DynamoDB를 적절하게 사용할 수 있습니다. 그리고 그에 걸맞게 DynamoDB는 기본적으로 꽤 까다로운 설계를 요구합니다.
키 (Key)
DynamoDB에는 파티션 키(Partition Key)와 정렬 키(Sort Key)라는 두 종류의 키가 존재합니다. 이 두 종류의 키를 테이블에 어떻게 구성하느냐가 바로 DynamoDB 설계의 핵심입니다.
파티션 키와 정렬 키를 테이블에 구성하는 방법은 두 가지입니다.
- 파티션 키를 사용하고, 정렬 키는 사용하지 않는 방법
- 파티션 키와 정렬 키를 동시에 사용하는 방법
파티션 키 (Partition key)
DynamoDB는 데이터를 ‘파티션’ 이라는 논리적 저장 공간에 분산 저장합니다. Partition key는 파티션을 특정하는 키로, 하나의 Partition key가 하나의 파티션에 대응됩니다.
파티션 키는 DynamoDB 성능의 핵심입니다. DynamoDB는 기본적으로 테이블 전체를 조회하지 않고, 파티션 키를 기반으로 특정 파티션 내의 데이터만 조회하기 때문에 높은 성능이 보장됩니다.
- 파티션 키는 테이블 내에 반드시 존재해야 하고, 하나만 존재해야 합니다.
- 테이블 내에 정렬 키가 존재하지 않을 경우, 데이터의 파티션 키는 테이블 내에서 고유한 값이어야 합니다.
- 일치 연산만 사용할 수 있습니다. 즉, DynamoDB에서 특정 데이터를 조회하기 위해서는, 반드시 데이터의 파티션 키를 알고 있어야 합니다. ****(단, 후술할 scan 메소드를 사용하는 경우는 예외입니다.)
정렬 키 (Sort key)
정렬 키는 파티션 내의 항목을 정렬하거나 필터링하는 데 사용됩니다. 따라서 데이터 조회 시 정렬 키만 단독으로 사용할 수는 없으며, 반드시 파티션 키와 함께 사용해야 합니다. 반대로 정렬 키가 존재하지만 정렬 키를 사용하지 않고 파티션 키만 단독으로 사용하여 데이터를 조회하는 것은 가능합니다.
- 정렬 키는 테이블 내에 반드시 존재할 필요는 없습니다. 최대 1개만 존재할 수 있습니다.
- 단, 후술할 Local Secondary Index를 사용하여 여러 개의 정렬 키가 존재하는 것처럼 테이블을 구성할 수 있습니다.
- 데이터의 정렬 키 값은 파티션 내에서 고유한 값이어야 합니다. 즉, 파티션 키와 정렬 키의 조합은 고유해야 합니다.
- 일치/불일치 연산, 비교 연산, begins_with 함수(특정 문자열으로 시작하는 문자열 검색) 사용이 지원됩니다.
키 조합하기
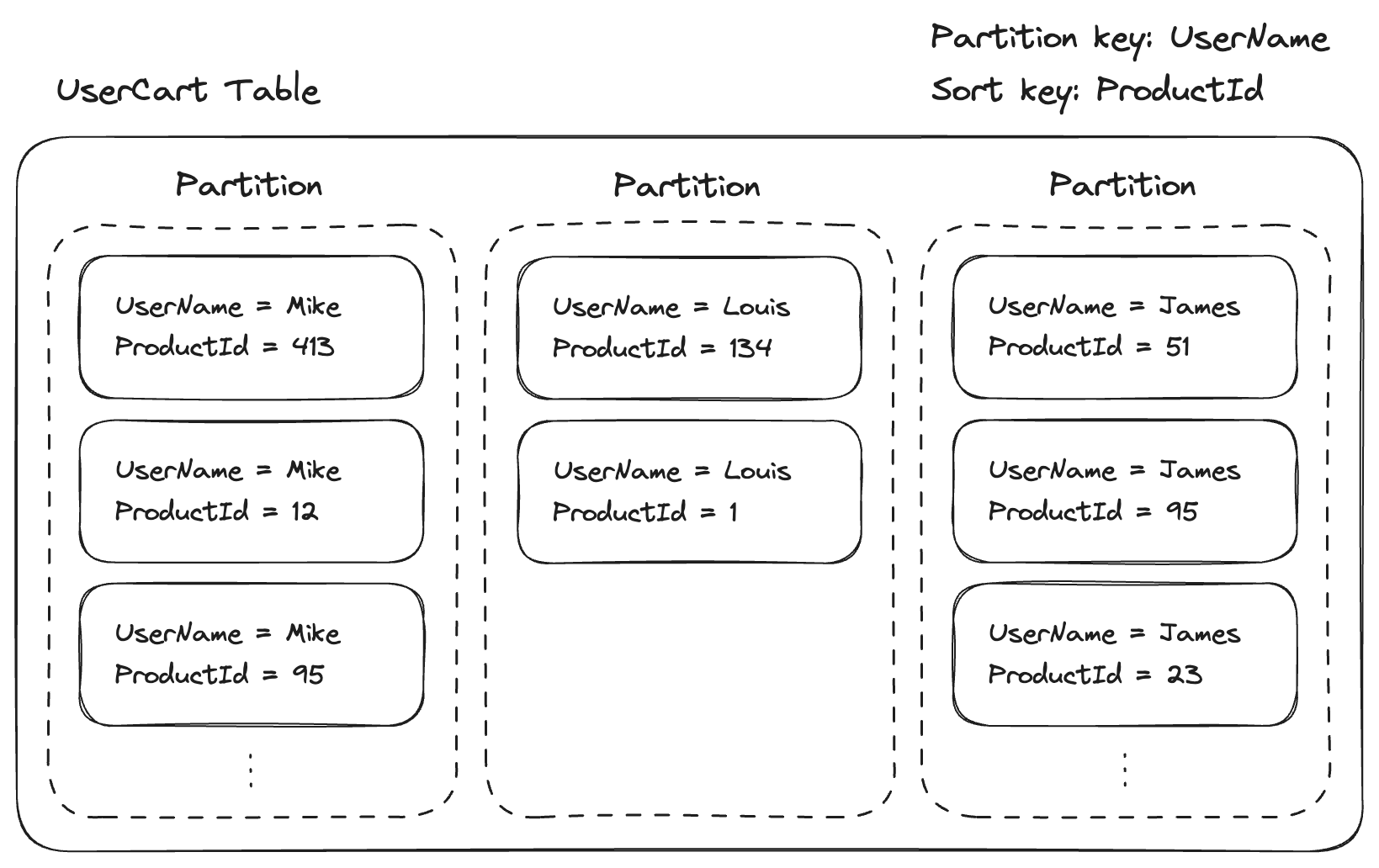
기본 키가 파티션 키와 정렬 키의 조합으로 이루어져 있는 테이블의 경우, 데이터가 대략 위와 같은 형태로 저장됩니다.
쇼핑몰의 간단한 장바구니 기능에 대한 데이터 저장이 필요하다고 가정해 보겠습니다. 데이터는 UserCart라는 이름의 테이블에 저장되고, 테이블의 파티션 키는 UserName, 정렬 키는 ProductId입니다.
파티션 키가 UserName이므로 테이블 내에는 각 유저에 맵핑되는 여러 파티션이 존재하게 됩니다. 그리고 각 파티션 내에 ProductId를 정렬 키로 유저가 담은 상품 데이터가 저장되게 됩니다.
Hot Partition
한 파티션에 대해서 대량의 읽기/쓰기 요청이 집중되는 현상을 핫 파티션이라고 합니다. 핫 파티션이 발생하면 파티션에 요청이 고르게 분산되지 않아 성능 저하 및 비용 증가가 발생할 수 있습니다.
예를 들어, 어떤 쇼핑몰의 상품 데이터를 다루는 테이블에서, 티셔츠에 대한 수요가 매우 높아 Partition key가 ‘tshirt’ 인 데이터들에 대해서 매우 많은 요청이 들어오는 경우를 생각해 볼 수 있습니다. 이 경우 ‘tshirt’ 파티션이 핫 파티션이 됩니다.
DynamoDB 설계 시에는 핫 파티션이 생기지 않게 하기 위해서, 되도록이면 데이터 간 파티션 키가 겹치지 않도록 설계하거나(High Cardinality), 특정 파티션 키의 데이터에 요청이 쏠리지 않도록 설계할 필요가 있습니다.
파티션이 너무 많으면 성능이 떨어지거나 돈이 많이 나오는 것이 아니냐는 걱정을 할 수도 있겠지만, DynamoDB는 데이터를 파티션에 균일하게 분배하는 것에 최적화되어 있는 DB이기에 아무 문제가 없습니다. AWS는 오히려 데이터 간 Partition key가 가능한 한 겹치지 않도록, 즉 최대한 많은 수의 파티션을 만드는 것을 권장합니다.
인덱스 (Index)
DynamoDB에는 크게 두 가지 제약이 존재합니다.
- 데이터를 조회할 때 해당 데이터의 파티션 키 값을 알고 있어야 합니다. (후술할 scan을 사용할 수도 있지만, 너무나도 비효율적입니다.)
- 데이터를 정렬하거나 필터링하는 데 사용되는 정렬 키가 테이블에 최대 1개만 존재할 수 있습니다.
위 두 제약을 극복하기 위해서, DynamoDB는 GSI와 LSI라는 두 종류의 인덱스를 지원합니다.
GSI (Global Secondary Index)
- 원본 테이블의 복제본을 만드는 방식이기 때문에, 테이블을 생성한 이후에도 추가, 삭제, 변경이 가능합니다.
- 원본 테이블과 다른 파티션 키와 정렬 키를 정의할 수 있습니다.
- 테이블당 최대 20개 존재할 수 있습니다.
LSI (Local Secondary Index)
- 테이블 생성 시만 정의할 수 있습니다. 테이블 생성 후에는 추가, 삭제, 변경이 불가능합니다.
- 파티션 키는 원본 테이블과 동일합니다. 정렬 키만 원본 테이블과 다른 형태로 정의할 수 있습니다.
- 테이블당 최대 5개 존재할 수 있습니다.
데이터 조회
DynamoDB에서 데이터를 조회는 방법은 크게 세 가지입니다.
- GetItem 메소드를 사용해서, 파티션 키와 정렬 키가 정확하게 일치하는 단일 항목을 조회하는 방법
- Query 메소드를 사용해서, 파티션 키가 일치하고 정렬 키의 조건에 맞는 항목들을 조회하는 방법
- Scan 메소드를 사용해서, 조건에 맞는 항목들을 조회하는 방법.
GetItem 메소드와 Query 메소드는 사용하기 전에 반드시 조회하고자 하는 항목의 파티션 키 값을 알고 있어야 합니다. 반면 Scan은 파티션 키와 정렬 키에 관계없이, 원하는 속성과 조건을 기반으로 데이터를 조회할 수 있습니다.
단, Scan 메소드는 테이블 내의 모든 데이터를 순회하고 조건에 맞는 데이터를 반환합니다. 큰 테이블일수록 리소스를 많이 사용하고 그만큼 비용도 증가하기 때문에, 되도록이면 사용하지 않는 것이 좋습니다.